

What does Big Data mean in the context of disaster response? Big (Crisis) Data refers to the relatively large volume, velocity and variety of digital information that may improve sense making and situational awareness during disasters. This is often referred to the 3 V’s of Big Data.
Volume refers to the amount of data (20 million tweets were posted during Hurricane Sandy) while Velocity refers to the speed at which that data is generated (over 2,000 tweets per second were generated following the Japan Earthquake & Tsunami). Variety refers to the variety of data generated, e.g., Numerical (GPS coordinates), Textual (SMS), Audio (phone calls), Photographic (satellite Imagery) and Video-graphic (YouTube). Sources of Big Crisis Data thus include both public and private sources such images posted as social media (Instagram) on the one hand, and emails or phone calls (Call Record Data) on the other. Big Crisis Data also relates to both raw data (the text of individual Facebook updates) as well as meta-data (the time and place those updates were posted, for example).
Ultimately, Big Data describe datasets that are too large to be effectively and quickly computed on your average desktop or laptop. In other words, Big Data is relative to the computing power—the filters—at your finger tips (along with the skills necessary to apply that computing power). Put differently, Big Data is “Big” because of filter failure. If we had more powerful filters, said “Big” Data would be easier to manage. As mentioned in previous blog posts, these filters can be created using Human Computing (crowdsourcing, microtasking) and/or Machine Computing (natural language processing, machine learning, etc.).
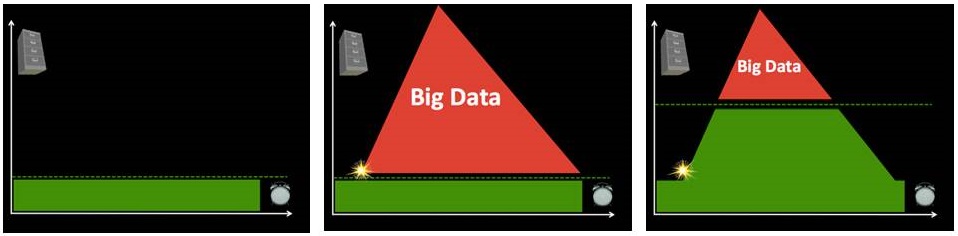
Take the [first] graph, for example. The horizontal axis represents time while the vertical one represents volume of information. On a good day, i.e., when there are no major disasters, the Digital Operations Center of the American Red Cross monitors and manually reads about 5,000 tweets. This “steady state” volume and velocity of data is represented by the green area. The dotted line just above denotes an organization’s (or individual’s) capacity to manage a given volume, velocity and variety of data. When disaster strikes, that capacity is stretched and often overwhelmed. More than 3 million tweets were posted during the first 48 hours after the Category 5 Tornado devastated Moore, Oklahoma, for example. What happens next is depicted in the [second] graph below.
Humanitarian and emergency management organizations often lack the internal surge capacity to manage the rapid increase in data generated during disasters. This Big Crisis Data is represented by the red area. But the dotted line can be raised. One way to do so is by building better filters (using Human and/or Machine Computing). Real world examples of Human and Machine Computing used for disaster response are highlighted here and here respectively.
A second way to shift the dotted line is with enlightened leadership [third graphic]. An example is the Filipino Government’s actions during the recent Typhoon. More on policy here. Both strategies (advanced computing & strategic policies) are necessary to raise that dotted line in a consistent manner.
See also:
- Big Data for Disaster Response: A List of Wrong Assumptions [Link]


