
The Rosetta Project is pleased to announce the Parallel Speech Corpus Project, a year-long volunteer-based effort to collect parallel recordings in languages representing at least 95% of the world’s speakers. The resulting corpus will include audio recordings in hundreds of languages of the same set of texts, each accompanied by a transcription. This will provide a platform for creating new educational and preservation-oriented tools as well as technologies that may one day allow artificial systems to comprehend, translate, and generate them.
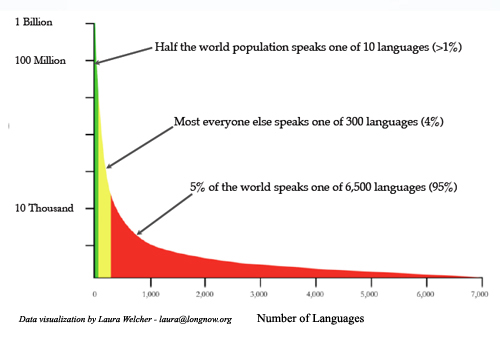
Huge text and speech corpora of varying degrees of structure already exist for many of the most widely spoken languages in the world—English is probably the most extensively documented, followed by other majority languages like Russian, Spanish, and Portuguese. Given some degree of access to these corpora (though many are not publicly accessible), research, education and preservation efforts in the ten languages which represent 50% of the world’s speakers (Mandarin, Spanish, English, Hindi, Urdu, Arabic, Bengali, Portuguese, Russian and Japanese) can be relatively well-resourced.
But what about the other half of the world? The next 290 most widely spoken languages account for another 45% of the population, and the remaining 6,500 or so are spoken by only 5%–this latter group representing the “long tail” of human languages:
(Thanks to @argotechnica)
July 21st, 02010 by Laine Stranahan


