

Crowdsourcing Crisis Information from Syria: Twitter API vs Firehose
Over 400 million tweets are posted every day. But accessing 100% of these tweets (say for disaster response purposes) requires access to Twitter’s “Firehose”. The latter, however, can be prohibitively expensive and also requires serious infrastructure to manage. This explains why many (all?) of us in the Crisis Computing & Humanitarian Technology space use Twitter’s “Streaming API” instead. But how representative are tweets sampled through the API vis-a-vis overall activity on Twitter? This is important question is posed and answered in this new study, which used Syria as a case study.
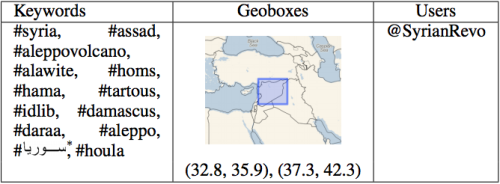
The analysis focused on “Tweets collected in the region around Syria during the period from December 14, 2011 to January 10, 2012.” The first dataset was collected using Firehose access while the second was sampled from the API. The tag clouds above (click to enlarge) displays the most frequent top terms found in each dataset. The hashtags and geoboxes used for the data collection are listed in the table below.
. . . . .
In terms of social network analysis, the the authors were able to show that “50% to 60% of the top 100 key-players [can be identified] when creating the networks based on one day of Streaming API data.” Aggregating more days’ worth of data “can increase the accuracy substantially. For network level measures, first in-depth analysis revealed interesting correlation between network centralization indexes and the proportion of data covered by the Streaming API.”
Read full post with graphs and other links.
Phi Beta Iota: There is enormous value in everything that the Crisis Mappers and the humanitarian technology folks do. However, a reliance on Western social media for indigenous understanding is treacherously dangerous. Just as US political science and international relations disciplines lost their way in the 1970's, substituting computer modeling and comparative statistics (based on Western assumptions) for field work and foreign language and history and culture studies, now the researchers are all too enamored of Twitter and other similar devices that exclude all those who are non-Western, not connected, or properly skeptical of the value of anything that limits you to 140 characters or whatever. Like the drunk looking for his keys under the streetlamp, these researchers will create value, but it will not be centered on the target as the target is defined by all those not on Twitter. This is one of the major reasons we consider the current intelligence-industrial complex promotion of more money for social media monitoring (for the really stupid, “SOCINT”) to be ignorant, unethical, and likely to retard the vastly more important advances that must be made with respect to the human factor: human intelligence collection in-country at the neighborhood level; all-language/all non-US sources inclusion; and desktop analytic tools for the all-source analyst. 20 years after we first pointed out these shortfalls, $1.25 trillion dollars after we first pointed out these short-falls, the US secret intelligence community is still unable to address any of the three.
See Also:
1976-2013: Analytic, Methodological, & Technical Models 2.0


