

Mind-shift, must have.
Supercomputing director bets $2,000 that we won’t have exascale computing by 2020
Joel Hruska
ExtremeTech, 17 May 2013
Over the past year, we’ve covered a number of the challenges facing the supercomputing industry in its efforts to hit exascale compute levels by the end of the decade. The problem has been widely discussed at supercomputing conferences, so we’re not surprised that Horst Simon, the Deputy Director at the Lawrence Berkeley National Laboratory’s NERSC (National Energy Research Scientific Computing Center), has spent a significant amount of time talking about the problems with reaching exascale speeds.
But putting up $2000 of his own money in a bet that we won’t hit exascale by 2020? That caught us off guard.
The exascale rethink
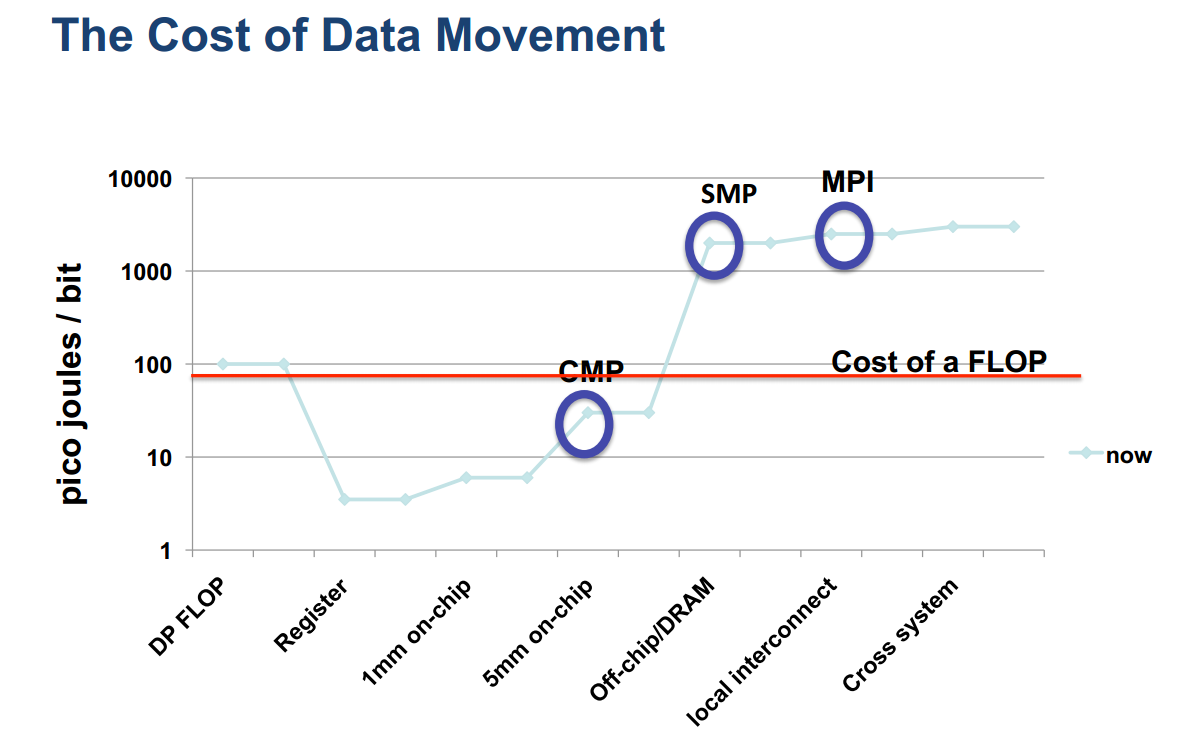
Simon lays out, in a 60+ page slideshow, why he doesn’t think we’ll hit the exascale threshold within seven years. The bottom line is this: Hitting exascale compute levels requires a fundamental rethink of virtually the entire computation process. One of the biggest problems standing in our way is power — not just the power required to run a task on a CPU, but the power required to share that data across the chip, node, and cluster. Data has to be written back to RAM, then shared across multiple systems. Caches must be kept coherent, calculation results written to storage, and new information loaded into RAM.
Power efficiency, measured on a per-core basis, is expected to continue improving for multi-core and many-core architectures, but interconnect power consumption hasn’t scaled nearly as well. This leads to a long-term problem — by 2018, it’ll cost more to move a FLOP off-die than to perform the calculation locally. This might seem like a trivial problem. At the consumer end of the market (and by consumer, I mean anything up to a dual-socket workstation), you’re right.
But that’s precisely where exascale-level problems stab our concept of efficiency in the back. One exaflop is 10 quintillion FLOPS per second. When you’re working with 18 zeroes, picojoules suddenly start adding up. It’s theoretically possible to hit exascale computing with current levels of technology if you can afford to dedicate 100 megawatts of power to the task, but the challenge is to bring exascale into the 20-30MW range.
Nvidia, Intel, and AMD (maybe) to the rescue… or not
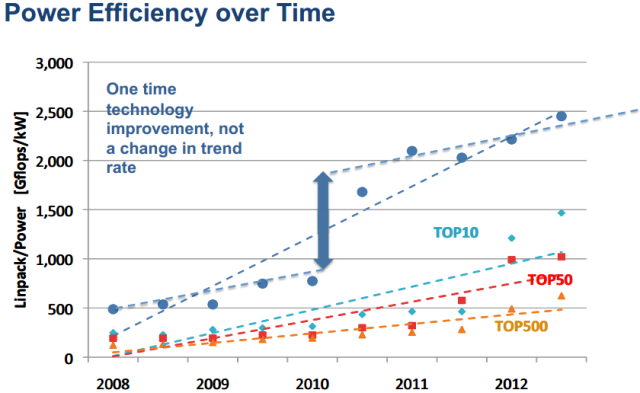
Many-core architectures have been billed as the solution to the short-term scaling problem. The good news is that they definitely helped — the most efficient systems in the Top500 list of supercomputers are all using Intel, Nvidia, or (in one case) AMD hardware to hit their targets.
The bad news is that this upgrade is basically a one-time deal. Supercomputing clusters that don’t currently use many-core architectures will continue to adopt them and will see benefits from doing so. Nvidia and Intel will deliver new products that improve performance-per-watt and increase efficiency. These improvements, however, are going to be iterative. That doesn’t mean many-core chips aren’t going to drive new records for performance efficiency — but it does mean that such improvements, in and of themselves, aren’t going to be enough to bridge the exascale gap.
But here’s the thing: What if the focus on “exascale” is actually the wrong way to look at the problem? It’s not an unprecedented question: The PC market clung to MHz as a primary measure of performance for more than two decades until Intel broke the system with the Pentium 4. Ironically, that break turned out to be a good idea long term. The marketing campaigns that companies like Apple and AMD launched in the late 1990s and early 2000s began communicating that MHz was a poor performance metric a few years before the multi-core transition and Core 2 Duo launch dumped MHz as a focus.
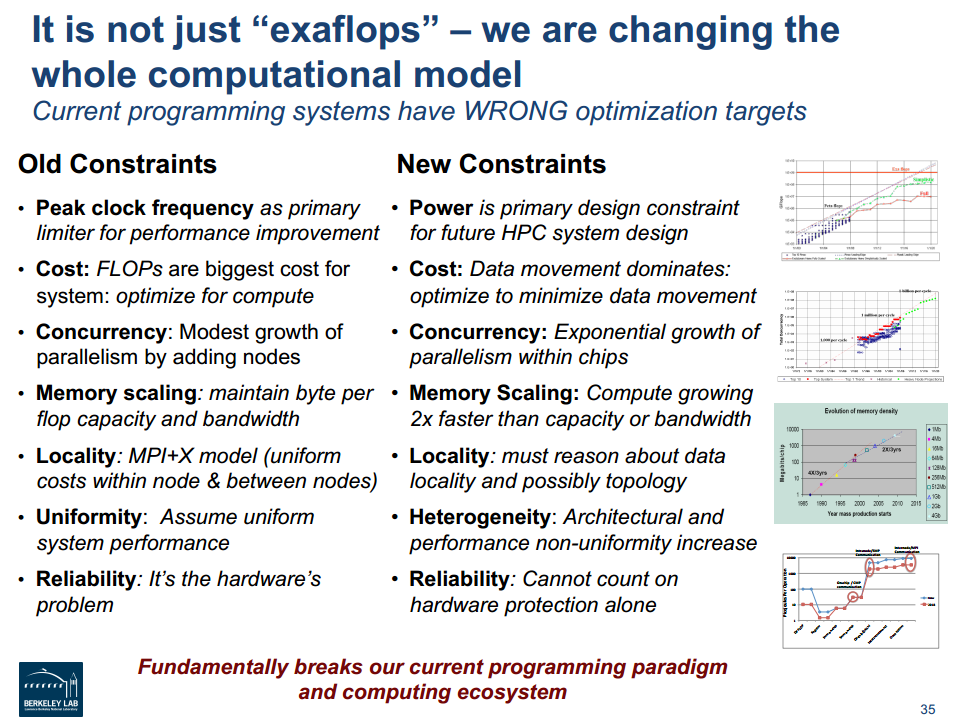
FLOPS has persisted as a metric in supercomputing even as core counts and system density has risen, but the peak performance of a supercomputer may be a poor measure of its usefulness. The ability to efficiently utilize a subset of the system’s total performance capability is extremely important. In the long term, FLOPS are easier than moving data across nodes. Taking advantage of parallelism becomes even more important. Keeping data local is a better way to save power than spreading the workload across nodes, because as node counts rise, concurrency consumes an increasing percentage of total system power.
Why exascale matters
The final slides of the presentation underline the facts of why exascale processing is so important, even if Simon doesn’t think we’ll get there in the next seven years. Better climate simulation, battery technology research, and internal combustion engine design all depend on it. Safeguarding the nation’s aging nuclear weapon reserves is a critical task for the next decade. And if we ever intend to simulate a human brain, exascale is a necessity.
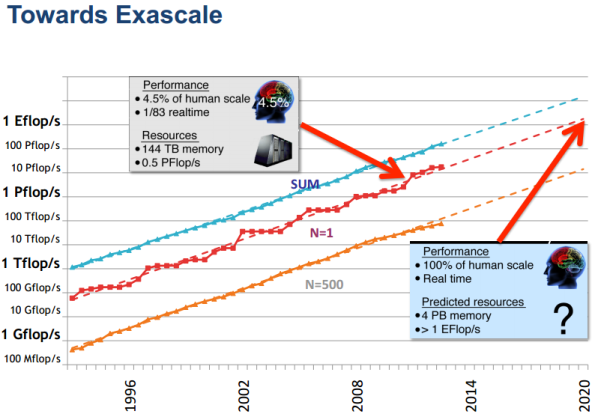
Right now, our best simulations are at 4.5% of human scale, running at 1/83 realtime speed. At one exaflop, we’re (potentially) up to human-scale and real-time processing, if we can leverage conventional CMOS effectively. But to put that in perspective, compare our brain’s efficiency against the projected best-case scenario for an exaflop system.
This is something John Hewitt covered extensively in a story earlier this year. The human brain is mindbogglingly efficient when compared to even the best semiconductors we’ll be able to build in 2020. Despite this, being able to simulate a mind — even at one million times the power consumption — would be an enormous step forward for technology. The overall point of Simon’s talk wasn’t that exascale is impossible, but that it’s vital, despite the high price tag, slow advancement, and the need to revisit virtually every assumption that’s driven supercomputing forward for the past 30 years.

Phi Beta Iota: Intelligence with integrity needs BOTH a proper respect for all eight tribes and all fifteen slides of “full spectrum Human Intelligence (HUMINT)” or humanity — harnessing, harvesting, and nurturing the brains of the five billion poor as well as the one billion rich — AND a holistic comprehensive architecture for computing and communications at a World Brain scale. We think about this a lot. The secret world (mostly NSA) has gamed the US Government concepts and development planning to the point that the National Science Foundation (NSF), to take one example, is a neutered side show. Worse, NSA is not about to change its retarded mind-set. OMB needs to manage on the basis of Whole of Government ethical evidence-based decision-support, and NSF needs to go for the whole enchilada in information and intelligent systems aspirations.
See Especially:
Anonymous Feedback on Robert Steele’s Appraisal of Analytic Foundations — Agreement & Extension
2014 Robert Steele: Appraisal of Analytic Foundations – Email Provided, Feedback Solicited – UPDATED
Robert Steele: Why Big Data is Stillborn (for Now) + Comments from EIN Technical Council
See Also:
2015 Steele's New Book
2014 Beyond OSA
2014 PhD Proposal
2014 Steele's Open Letter
2014 UN @ Phi Beta Iota
2013 Intelligence Future
2012 Academy Briefing
1989+ Intelligence Reform
1976+ Intelligence Models 2.1
1957+ Decision Support Story


