

Speeding Up Search: The Challenge of Multiple Bottlenecks
I read “Search at Scale Shows ~30,000X Speed Up.” I have been down this asphalt road before, many times in fact. The problem with search and retrieval is that numerous bottlenecks exist; for example, dealing with exceptions (content which the content processing system cannot manipulate).
I wish to list some of the speed bumps which the write does not adequately address or, in some cases, acknowledge:
- Content flows are often in the terabit or petabit range for certain filtering and query operations., One hundred million won’t ring the bell.
- This is the transform in ETL operations. Normalizing content takes some time, particularly when the historical on disc content from multiple outputs and real-time flows from systems ranging from Cisco Systems intercept devices are large. Please, think in terms of gigabytes per second and petabytes of archived data parked on servers in some countries’ government storage systems.
- Populating an index structure with new items also consumes time. If an object is not in an index of some sort, it is tough to find.
- Shaping the data set over time. Content has a weird property. It evolves. Lowly chat messages can contain a wide range of objects. Jump to today’s big light bulb which illuminates some blockchains’ ability house executables, videos, off color images, etc.
- Because IBM inevitably drags Watson to the party, keep in mind that Watson still requires humans to perform gorilla style grooming before it’s show time at the circus. Questions have to be considered. Content sources selected. The training wheels bolted to the bus. Then trials have to be launched. What good is a system which returns off point answers?

ROBERT STEELE: The Information Technology (IT) industry is retarded by design. From being designed for machine to machine communications without regard to data integrity at the line item level, to complicity with NSA back-doors to the migration and mutation of Application Program Interfaces (API), the IT industry is shit. We process 1% of Big Data (which in turn is 1% of what can be known) precisely because the IT industry is shit. A new era is about to being, one that implements Doug Englebart's Open Hypertextdocument System (OHS), IDEN A (Japan) concept of crypto at credit card speed, and Kaliya Hamlin Young's vision of individual sovereignty with full rights of anonymity, identity, privacy, and security at the paragraph level.
Below is a graphic that Robert Garigue (RIP) and I put together in the late 1990's — the IT industry still does not get this because they are not being held accountable by the public for due diligence in communications and computing — we need to kill centralized computing, and we need to kill electromagnetic pollution and mass surveillance at the same time. This is going to happen by 2024 at the latest, with the alternative media and conscious public being “safe” by 2020.
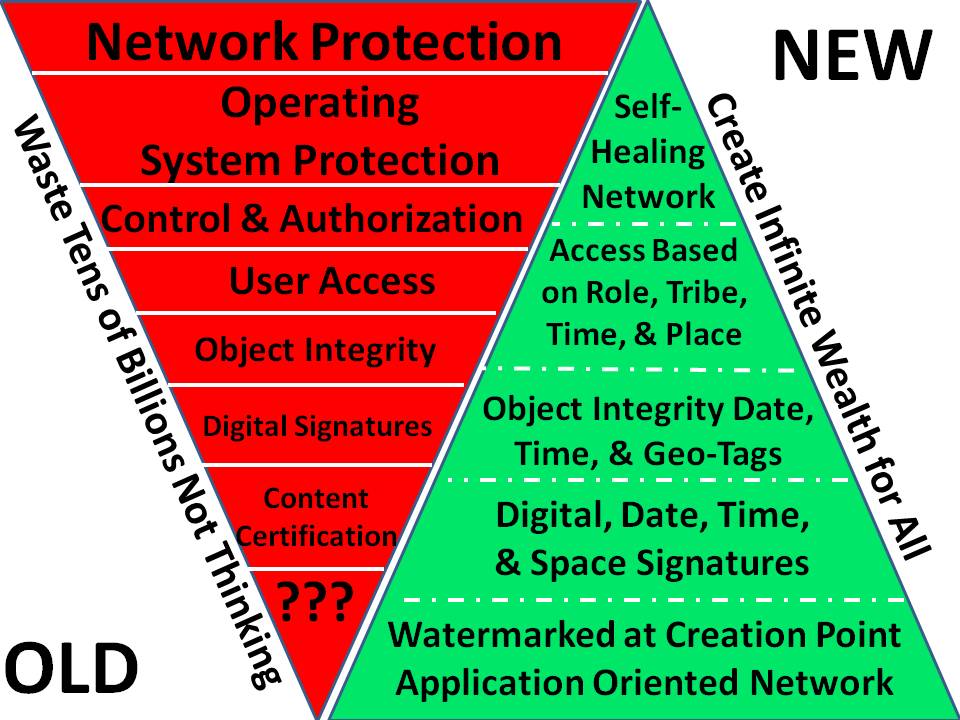
It is not too late to attend the conference (below) 3-5 April in Mountain View. Kaliya and her network are the center of gravity for positive change.
See Especially:
Steele, Robert. “Creating a Post-Western Independent Internet: An Open Source Internet Can Create Peace and Prosperity for All,” Russian International Affairs Council, February 5, 2018.
Steele, Robert, “How The Deep State Controls Social Media and Digitally Assassinates Critics: #GoogleGestapo – Censorship & Crowd-Stalking Made Easy,” American Herald Tribune, November 7, 2017.
Steele, Robert. For the President of the United States of America Donald Trump: Subject: EradicatingFake News and False Intelligence with an Open Source Agency That Also SupportsDefense, Diplomacy, Development, & Commerce (D3C) Innovation to Stabilize World. Earth Intelligence Network, 2017.
Robert Steele: Core Works for Those New to My Work
See Also:
Autonomous Internet @ Phi Beta Iota


