 PinePhone is a a LINUX open source smartphone capable of running Ubuntu touch and Sailfish OS.
PinePhone is a a LINUX open source smartphone capable of running Ubuntu touch and Sailfish OS.
Tip of the Hat to Steve Vervaecke.

The truth at any cost lowers all other costs — curated by former US spy Robert David Steele.
PinePhone is a a LINUX open source smartphone capable of running Ubuntu touch and Sailfish OS.
Tip of the Hat to Steve Vervaecke.

Using Crowd Computing to Analyze UAV Imagery for Search & Rescue Operations
My brother recently pointed me to this BBC News article on the use of drones for Search & Rescue missions in England’s Lake District, one of my favorite areas of the UK. The picture below is one I took during my most recent visit. In my earlier blog post on the use of UAVs for Search & Rescue operations, I noted that UAV imagery & video footage could be quickly analyzed using a microtasking platform (like MicroMappers, which we used following Typhoon Yolanda). As it turns out, an enterprising team at the University of Central Lancashire has been using microtasking as part of their UAV Search & Rescue exercises in the Lake District.

Every year, the Patterdale Mountain Rescue Team assists hundreds of injured and missing persons in the North of the Lake District. “The average search takes several hours and can require a large team of volunteers to set out in often poor weather conditions.” So the University of Central Lancashire teamed up with the Mountain Rescue Team to demonstrate that UAV technology coupled with crowdsourcing can reduce the time it takes to locate and rescue individuals.
Video: Humanitarian Response in 2025
I gave a talk on “The future of Humanitarian Response” at UN OCHA’s Global Humanitarian Policy Forum (#aid2025) in New York yesterday. More here for context. A similar version of the talk is available in the video presentation below.
Some of the discussions that ensued during the Forum were frustrating albeit an important reality check. Some policy makers still think that disaster response is about them and their international humanitarian organizations. They are still under the impression that aid does not arrive until they arrive. And yet, empirical research in the disaster literature points to the fact that the vast majority of survivals during disasters is the result of local agency, not external intervention.

I’ve been invited to give a “very provocative talk” on what humanitarian response will look like in 2025 for the annual Global Policy Forum organized by the UN Office for the Coordination of Humanitarian Affairs (OCHA) in New York. I first explored this question in early 2012 and my colleague Andrej Verity recently wrote up this intriguing piece on the topic, which I highly recommend; intriguing because he focuses a lot on the future of the pre-deployment process, which is often overlooked.
Continue reading “Patrick Meier: Humanitarian Response in 2025”

Forget about Growth Hacking, the future is in the Collaborative Economy
VIDEO
Anyone working in digital can somewhat relate to the overuse of loosely defined marketing words – think ‘big data’ or ‘cloud computing’ (bzzzz). Growth hacking seems to be just another one of them.
In colloquial terms, growth hacking is associated with the exploitation of loopholes and the use of illegal techniques online to grow business development. Of course, in some cases this has been reality. When PayPal was first used on eBay, it was actually breaching the retailer’s T&C’s. Similarly, when Airbnb first started they poached their customers from Craigslist by spamming listings and inviting users to join their directory instead.
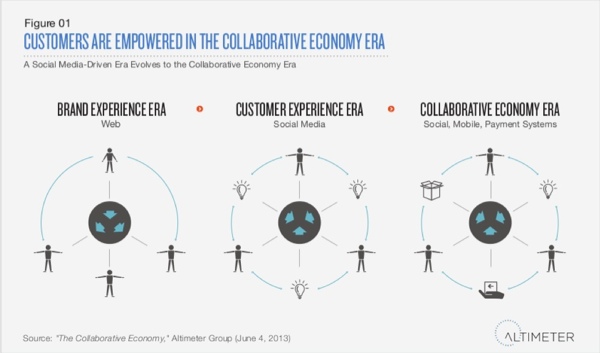
However, growth hacking can also simply be described as the ingenious use of tools, platforms and environments for business development, online AND offline – Google campus in East London, for example, is a good case of growth hacking taking place offline as start-ups use a shared working environment to maximise their potential. Online, growth hacking is the use of tracking and metric tools that teach us where our time is best spent; and the leveraging of platforms where target audiences and key players are.
‘Hacking’ does not necessarily equal to detrimental consequences for larger corporations either. Indeed, Paypal was then bought by eBay, and when Airbnb developed its interface it added the option to ‘post to Craigslist’.
Combining Radio, SMS and Advanced Computing for Disaster Response
I’m headed to the Philippines this week to collaborate with the UN Office for the Coordination of Humanitarian Affairs (OCHA) on humanitarian crowdsourcing and technology projects. I’ll be based in the OCHA Offices in Manila, working directly with colleagues Andrej Verity and Luis Hernando to support their efforts in response to Typhoon Yolanda. One project I’m exploring in this respect is a novel radio-SMS-computing initiative that my colleague Anahi Ayala (Internews) and I began drafting during ICCM 2013 in Nairobi last week. I’m sharing the approach here to solicit feedback before I land in Manila.

The “Radio + SMS + Computing” project is firmly grounded in GSMA’s official Code of Conduct for the use of SMS in Disaster Response. I have also drawn on the Bellagio Big Data Principles when writing up the in’s and out’s of this initiative with Anahi. The project is first and foremost a radio-based initiative that seeks to answer the information needs of disaster-affected communities.
Continue reading “Patrick Meier: Combining Radio, SMS, and Advanced Computing for Disaster Response”
Opening Keynote Address at CrisisMappers 2013
Welcome to Kenya, or as we say here, Karibu! This is a special ICCM for me. I grew up in Nairobi; in fact our school bus would pass right by the UN every day. So karibu, welcome to this beautiful country (and continent) that has taught me so much about life. Take “Crowdsourcing,” for example. Crowdsourcing is just a new term for the old African saying “It takes a village.” And it took some hard-working villagers to bring us all here. First, my outstanding organizing committee went way, way above and beyond to organize this village gathering. Second, our village of sponsors made it possible for us to invite you all to Nairobi for this Fifth Annual, International Conference of CrisisMappers (ICCM).

I see many new faces, which is really super, so by way of introduction, my name is Patrick and I develop free and open source next generation humanitarian technologies with an outstanding team of scientists at the Qatar Computing Research Institute (QCRI), one of this year’s co-sponsors.
Continue reading “Patrick Meier: Opening Address to CrisisMappers 2013”
