ABOVE IS FULL PRESENTATION BELOW IS ORIGINAL POST WITH FAST FORWARD LINK & POST
Phi Beta Iota: We strongly recommend watching the full presentation. This is “ground zero” for the future of intelligence, along with OSE and M4IS2.

The truth at any cost lowers all other costs — curated by former US spy Robert David Steele.

Norconex Offers Open Source HTTP Crawler
Most commercial enterprise search vendors offer their own HTTP crawler, and several are open-source. One new entry to the field stands out, though, for its odd blend of web and enterprise search functionality. In the post, “Norconex Gives Back to Open-Source,” Norconex describes their crawler and associated libraries:
“The Norconex HTTP Collector is an HTTP Crawler meant to give the greatest flexibility possible for developers and integrators. It makes it easy for Java developers to add custom features, so no one will get stuck again when dealing with odd requirements, difficult websites, or close-source crawler limitations. . . . The HTTP collector can be used stand-alone or embedded as a library in your own software.
“Norconex may release other collectors for various data sources in the future. In the meantime, we have encapsulated the document parsing process and sending of parsed data to your target search engine or repository into two separate libraries. We are releasing them as Norconex Importer and Norconex Committer.”
Norconex tells us that they focused on a simple configuration, as well as providing features that cannot be found in some existing crawlers. The enterprise search firm was founded in 2007 and is based in Ottawa, Canada.
Cynthia Murrell, July 16, 2013
Sponsored by ArnoldIT.com, developer of Augmentext

If you are looking for your ideal content curation toolkit here is my new completely updated supermap, listing in over 30 categories all of the tools and services you may need to curate any content, from video to news. This new supermap includes all of the tools and services that were already listed on NewsMaster Toolkit, with the addition of 25 new tools and with a much better organization of categories and labels. My choice for organizing and recreating this supermap has now fallen on Pearltrees, the only content curation tool that can easily handle most of my key requirements for such a large collection of tools. Nonetheless there are over 400 tools listed in this supermap, Pearltrees makes it a breeze to navigate through them, and to add new ones to the relevant branches. The supermap is now being updated daily.

P.S.: I already feel the need for having a PRO account, which could allow me to further edit the pearls collected, to preserve original web pages saved, and to add images to pearls that weren't able to capture one from the web.
Enjoy the new supermap here: http://bit.ly/ContentCurationToolsSupermap. Try it out and let me know what you think. (*and if you think I am missing some tools or can improve with my taxonomy, feel free to send me in your suggestions!)

Marco Arment the creator of Instapaper, has an excellent and provocative piece on why Google is closing down all of its RSS appendages (they just closed also the RSS feeds in Google Alerts) and the logic behind this strategy.
He writes: “Officially, Google killed Reader because “over the years usage has declined”.1 I believe that statement, especially if API clients weren’t considered “usage”, but I don’t believe that’s the entire reason.
The most common assumption I’ve seen others cite is that “Google couldn’t figure out how to monetize Reader,” or other variants about direct profitability. I don’t believe this, either. Google Reader’s operational costs likely paled in comparison to many of their other projects that don’t bring in major revenue, and I’ve heard from multiple sources that it effectively had a staff of zero for years. It was just running, quietly serving a vital role for a lot of people.”
“The bigger problem is that they’ve abandoned interoperability. RSS, semantic markup, microformats, and open APIs all enable interoperability, but the big players don’t want that — they want to lock you in, shut out competitors, and make a service so proprietary that even if you could get your data out, it would be either useless (no alternatives to import into) or cripplingly lonely (empty social networks).
Google resisted this trend admirably for a long time and was very geek- and standards-friendly, but not since Facebook got huge enough to effectively redefine the internet and refocus Google’s plans to be all-Google+, all the time.4”

Mobile security startup Bluebox Security has unearthed a vulnerability in Android’s security model which it says means that the nearly 900 million Android phones released in the past four years could be exploited, or some 99% of Android devices. The vulnerability has apparently been around since Android v1.6 (Donut), and was disclosed by the firm to Google back in February. The Samsung Galaxy S4 has already apparently been patched.
It’s likely that Google is working on a patch for the vulnerability. We’ve reached out to the company for comment and will update this story with any response.
Bluebox intends to detail the flaw at the Black Hat USA conference at the end of this month but in the meanwhile it’s written a blog delving into some detail. The vulnerability apparently allows a hacker to turn a legitimate app into a malicious Trojan by modifying APK code without breaking the app’s cryptographic signature. Bluebox says the flaw exploits discrepancies in how Android apps are cryptographically verified and installed. Specifically it allows a hacker to change an app’s code, leaving its cryptographic signature unchanged — thereby tricking Android into believing the app itself is unchanged, and allowing the hacker to wreak their merry havoc.

There was a lot of talk about software agents about ten years ago — computer code that would seek, filter, and deliver information specific to your interests I have not tried this yet, but I'm interested that people are trying with today's technology — and that RSS is one of its building blocks.
Introducing Primal Assistants: A framework for software agents
Primal does a lot of heavy lifting in knowledge representation and content filtering. If you ask it to grab you some relevant content around your interests, it will do precisely that.
 But what if you don’t want to have to ask? Search engines are fantastic, but they still require that you go to them and then try to figure out how to formulate your query in a way that gets you decent results.
But what if you don’t want to have to ask? Search engines are fantastic, but they still require that you go to them and then try to figure out how to formulate your query in a way that gets you decent results.
Primal already has the ability to understand what you want, and we’re now working on some technology that will let Primal deliver you the content that you truly care about before you know you want it.
Read on to learn more about Primal’s new software agent and content streaming framework.
What we’ve got cooking
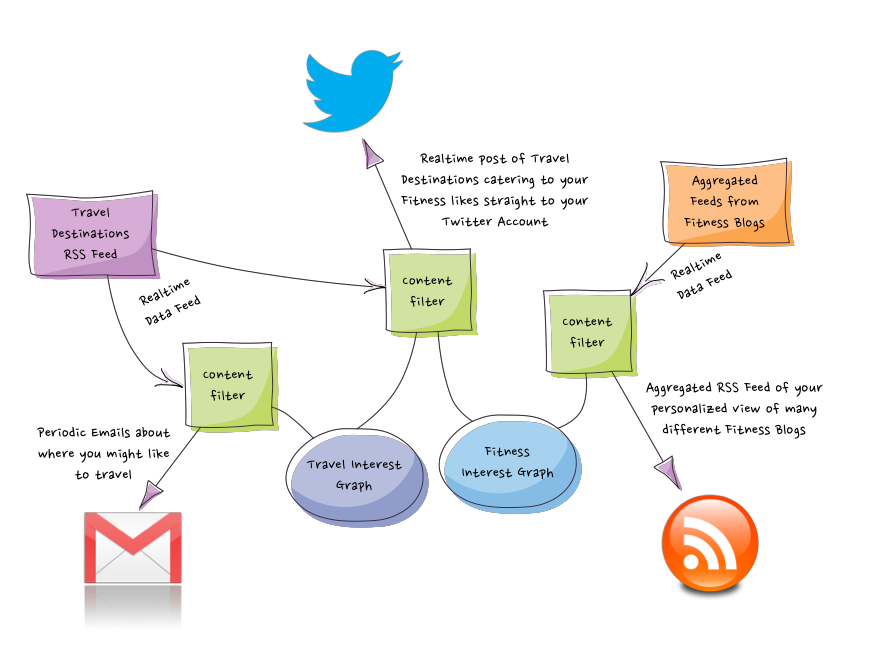
If you want Primal to bring you the content you care about, or send that content to someone else on your behalf, or mix it all up in a blender so you can drink it in your morning protein shake… no problem.Let’s say you have interests in Fitness and Travel. You’ve told Primal about these interests and Primal has dutifully created an interest graph to represent them. Now, you want to filter massive amounts of content through these interests as it becomes available, and route that to various places on your behalf.
Continue reading “Howard Rheingold: Primal Assistants – Personal Software Agents”

Free Software Supporter
Issue 63, June 2013
TABLE OF CONTENTS
Continue reading “Richard Stallman: Free Software Supporter Issue 63, June 2013”
