
 Emin Gun Sirer: Good post [by David Rosenthal] on why peer to peer storage projects face an uphill battle, which will likely end downhill, in Amazon's lap.
Emin Gun Sirer: Good post [by David Rosenthal] on why peer to peer storage projects face an uphill battle, which will likely end downhill, in Amazon's lap.
Full text of post below the line as a safety copy.
Phi Beta Iota: Absolutely essential reading. Robert Steele comments at end.
I'm David Rosenthal, and this is a place to discuss the work I'm doing in Digital Preservation.
The Four Most Expensive Words in the English Language
There are currently a number of attempts to deploy a cryptocurrency-based decentralized storage network, including MaidSafe, FileCoin, Sia and others. Distributed storage networks have a long history, and decentralized, peer-to-peer storage networks a somewhat shorter one. None have succeeded; Amazon's S3 and all other successful network storage systems are centralized.
Despite this history, initial coin offerings for these nascent systems have raised incredible amounts of “money”, if you believe the heavily manipulated “markets”. According to Sir John Templeton the four words are “this time is different”. Below the fold I summarize the history, then ask what is different this time, and how expensive is it likely to be?
The idea that the edge of the Internet has vast numbers of permanently connected, mostly-empty hard disks that could be corralled into a peer-to-peer storage system that was free, or at least cheap, while offering high reliability and availability has a long history. The story starts:
A long, long time ago in a computer far, far away….
The realization that networked personal computers need a shared, remote file system in addition to their local disk, like many things, starts with the Xerox Alto and its Interim File Server, designed and implemented by David R. Boggs and Ed Taft in the late 70s. As IP networking started to spread in the early 80s, CMU's Andrew project started work in 1983 on the Andrew file system, followed in 1984 by Sun's work on NFS (RFC1094). Both aimed to provide a Unix-like file system API to processes on client computers, implemented by a set of servers. This API was later standardized by POSIX.
Both the Andrew File System and NFS started from the idea that workstation disks were small and expensive, so the servers would be larger computers with big disks, but NFS rapidly became a way that even workstations could share their file systems with each other over a local area network. In the early 90s people noticed that workstation CPUs were idle a lot of the time, and together with the shared file space this spawned the idea of distributing computation across the local network:
The workstations were available more than 75% of the time observed. Large capacities were steadily available on an hour to hour, day to day, and month to month basis. These capacities were available not only during the evening hours and on weekends, but during the busiest times of normal working hours.
By the late 90s the size of workstation and PC disks had increased and research, for example at Microsoft, showed these disks were also under-utilized:
We found that only half of all disk space is in use, and by eliminating duplicate files, this usage can be significantly reduced,depending on the population size. Half of all machines are up and accessible over 95% of the time, and machine uptimes are randomly correlated. Machines that are down for less than 72 hours have a high probability of coming back up soon. Machine lifetimes are deterministic, with an expected lifetime of around 300 days. Most machines are idle most of the time, and CPU loads are not correlated with the fraction of time a machine is up and are weakly correlated with disk loads.
This gave rise to the idea that the free space in workstation disks could be aggregated, first into a local network file system, and then into a network file system that spanned the Internet. Intermemory (also here), from NEC's Princeton lab in 1998, was one of the first, but there have been many others, such as Berkeley's Oceanstore (project papers) from 2000.
A true peer-to-peer architecture would eliminate the central organization and was thought to have many other advantages. In the early 2000s this led to a number of prototypes, including FARSITE, PAST/Pastiche and CFS, based on the idea of symmetry; peers contributed as much storage to the network as they consumed at other peers:
In a symmetric storage system, node A stores data on node B if and only if B also stores data on A. In such a system, B can periodically check to see if its data is still held by A, and vice versa. Collectively, these pairwise checks ensure that each node contributes as it consumes, and some systems require symmetry for exactly this reason [6, 18].
(NB – replication meant that the amount of storage consumed was greater than the amount of data stored. Peers wanting reliability had to build their own replication strategy by symmetrically storing data at multiple peers.).
I am shocked, shocked to find that cheating is going on in here
These systems were vulnerable to the problem that afflicted Gnutella, Napster and other file-sharing networks, that peers were reluctant to contribute, and lied about their resources. The Samsara authors wrote:
Several mechanisms to compel storage fairness have been proposed, but all of them rely on one or more features that run counter to the goals of peer-to-peer storage systems. Trusted third parties can enforce quotas and certify the rights to consume storage [23] but require centralized administration and a common domain of control. One can use currency to track the provision and consumption of storage space [16], but this requires a trusted clearance infrastructure. Finally, certified identities and public keys can be used to provide evidence of storage consumption [16, 21, 23], but require a trusted means of certification. All of these mechanisms require some notion of centralized, administrative overhead—precisely the costs that peer-to-peer systems are meant to avoid.
Samsara from 2003 was a true peer-to-peer system which:
enforces fairness in peer-to-peer storage systems without requiring trusted third parties, symmetric storage relationships, monetary payment, or certified identities. Each peer that requests storage of another must agree to hold a claim in return—a placeholder that accounts for available space. After an exchange, each partner checks the other to ensure faithfulness. Samsara punishes unresponsive nodes probabilistically. Because objects are replicated, nodes with transient failures are unlikely to suffer data loss, unlike those that are dishonest or chronically unavailable.
As far as I know Samsara never got into production use.
From each according to his ability, to each according to his needs
At the same time Brian Cooper and Hector Garcia-Molina proposed an asymmetric system of “bid trading”:
a mechanism where sites conduct auctions to determine who to trade with. A local site wishing to make a copy of a collection announces how much remote space is needed, and accepts bids for how much of its own space the local site must “pay” to acquire that remote space. We examine the best policies for determining when to call auctions and how much to bid, as well as the effects of “maverick” sites that attempt to subvert the bidding system. Simulations of auction and trading sessions indicate that bid trading can allow sites to achieve higher reliability than the alternative: a system where sites trade equal amounts of space without bidding.
The mechanisms these systems developed to enforce symmetry or trading were complex, and it was never really clear that they were proof against attack, because they were never deployed at enough scale to get attacked.
Its 10pm, do you know where your bytes are?
The API exported by services like these falls into one of two classes:
- The “file system and object store” model, in which the client sees a single service provider. The service decides which peer stores what; the client has no visibility into where the data lives.
- The “storage marketplace” model, in which the client sees offers from peers to store data at various prices, whether in space or cash. The client chooses where to store what.
There is a significant advantage of the “file and object store” model. Because the client transfers data to and from the service, the service can divide the data into shards and use erasure coding to deliver reliability at a low replication factor. In the “storage marketplace” model the client transfers data to and from the peer from which it decides to buy; the client needing reliability has to buy service from multiple peers and shard the data across them itself, greatly increasing the complexity of using the service. In principle, in the “file and object store” model the service can run an internal market, purchasing the storage from the most competitive peers.
If at first you don't succeed …
Why didn't Intermemory, Oceanstore, FARSITE, Pastiche, CFS, Samsara and all the others succeed? Four years ago I identified a number of reasons:
- Their model of the edge of the Internet was that there were a lot of desktop computers, continuously connected and powered-up, with low latency and no bandwidth charges, and with 3.5″ hard disks that were mostly empty. Since then, the proportion of the edge with these characteristics has become vanishingly small.
- In many cases, for example Samsara, the idea was that participants would contribute disk space and, in return, be entitled to store data in the network. Mechanisms were needed to enforce this trade, to ensure that peers actually did store the data they claimed to, and these mechanisms turned out to be hard to make attack-resistant.
- Even if erasure coding were used to reduce the overall replication factor, it would still be necessary for participants to contribute significantly more space than they could receive in return. And the replication factor would need to be higher than in a centrally managed storage network.
- I don't remember any of the peer-to-peer systems in which participants could expect a monetary reward. In the days when storage was thought to be effectively free, why would participants need to be paid? Alas, storage is a lot less free than it used to be.
Now I can add two more:
- The centralized systems such as Intermemory and Oceanstore never managed to set up the administrative and business mechanisms to channel funds from users to storage service suppliers, let alone the marketing and sales needed to get users to pay.
- The idea that peer-to-peer technology could construct a reliable long-term storage infrastructure from a self-organizing set of unreliable, marginally motivated desktops wasn't persuasive. And in practice it is really hard to pull off.
Bandwidth and hard disk space may be cheap, but they aren't free.
Both Intermemory and Oceanstore were proposed as subscription services; users paid a monthly fee to a central organization that paid for the network of servers. In practice the business of handling these payments never emerged. The symmetric systems used a “payment in kind” model to avoid the need for a business of this kind.
The idea that the Internet would enable automated “micro-payments” has a history as long as that of distributed storage, but I won't recount it. Had there been a functional micro-payment system it is possible that a distributed or even decentralized storage network could have used it and succeeded. Of course, Clay Shirky had pointed out the reason there wasn't a functional Internet micro-payment system back in 2000:
The Short Answer for Why Micropayments Fail
Users hate them.
The Long Answer for Why Micropayments Fail
Why does it matter that users hate micropayments? Because users are the ones with the money, and micropayments do not take user preferences into account.
One of Satoshi Nakamoto's critiques of existing payment systems when he proposed Bitcoin was that they were incapable of micro-payments. Alas, Bitcoin has turned out to be incapable of micro-payments as well. But as Bitcoin became popular, in 2014 a team at Microsoft and U. Maryland proposed:
a modification to Bitcoin that repurposes its mining resources to achieve a more broadly useful goal: distributed storage of archival data. We call our new scheme Permacoin. Unlike Bitcoin and its proposed alternatives, Permacoin requires clients to invest not just computational resources, but also storage. Our scheme involves an alternative scratch-off puzzle for Bitcoin based on Proofs-of-Retrievability (PORs). Successfully minting money with this SOP requires local, random access to a copy of a file. Given the competition among mining clients in Bitcoin, this modified SOP gives rise to highly decentralized file storage, thus reducing the overall waste of Bitcoin.
This wasn't clients directly paying for storage, the funds for storage came from the mining rewards and transaction fees. And, of course, the team were behind the times. Already by 2014 the Bitcoin mining network wasn't really decentralized.
After that long preamble, we can get to the question: What is different about the current rash of cryptocurrency-based storage services from the long line of failed predecessors? There are two big differences.
The first is the technology, not so much the underlying storage technology but more the business and accounting technology that is intended to implement a flourishing market of storage providers. The fact that these services are addressing the problem of a viable business model for providers in a decentralized storage market is a good thing. The lack of a viable business model is a big reason why none of the predecessors succeeded
Since the key property of a cryptocurrency-based storage service is a lack of trust in the storage providers, Proofs of Space and Time are required. As Bram Cohen has pointed out, this is an extraordinarily difficult problem at the very frontier of research. No viable system has been deployed at scale for long enough for reasonable assurance of its security. Thus the technology difference between these systems and their predecessors is at best currently a maybe.
However:
Remember It Isn't About The Technology? It started with a quote from Why Is The Web “Centralized”? :
What is the centralization that decentralized Web advocates are reacting against? Clearly, it is the domination of the Web by the FANG (Facebook, Amazon, Netflix, Google) and a few other large companies such as the cable oligopoly.
These companies came to dominate the Web for economic not technological reasons.
The second thing that is different now is that the predecessors never faced an entrenched incumbent in their market. Suppose we have a cryptocurrency-based peer-to-peer storage service. Lets call it P2, to emphasize that the following is generic to all cryptocurrency-based storage services.
To succeed P2 has to take market share from the centralized storage services that dominate the market for Internet-based storage. In practice it means that it has to take market share from Amazon's S3, which has dominated the market since it was launched in 2006. How do they stack up against each other?
- P2 will be slower than S3, because the network between the clients and the peers will be slower than S3's infrastructure, and because S3 doesn't need the overhead of enforcement.
- P2 will lack access controls, so clients will need to encrypt everything they store.
- P2 will be less reliable, since a peer stores a single copy where S3 stores 3 with geographic diversity. P2 clients will be a lot more complex than S3 clients, since they need to implement their own erasure coding to compensate for the lack of redundancy at the service.
- P2's pricing will be volatile, where S3's is relatively stable.
- P2's user interface and API will be a lot more complex than S3's, because clients need to bid for services in a marketplace using coins, and bid for coins in an exchange using “fiat currency”.
Clearly, P2 cannot charge as much per gigabyte per month as S3, since it is an inferior product. P2's pricing is capped at somewhat less than S3's. But the cost base for a P2 peer will be much higher than S3's cost base, because of Amazon's massive economies of scale, and its extraordinarily low cost of capital. So the business of running a P2 peer will have margins much lower than Amazon's notoriously low margins.
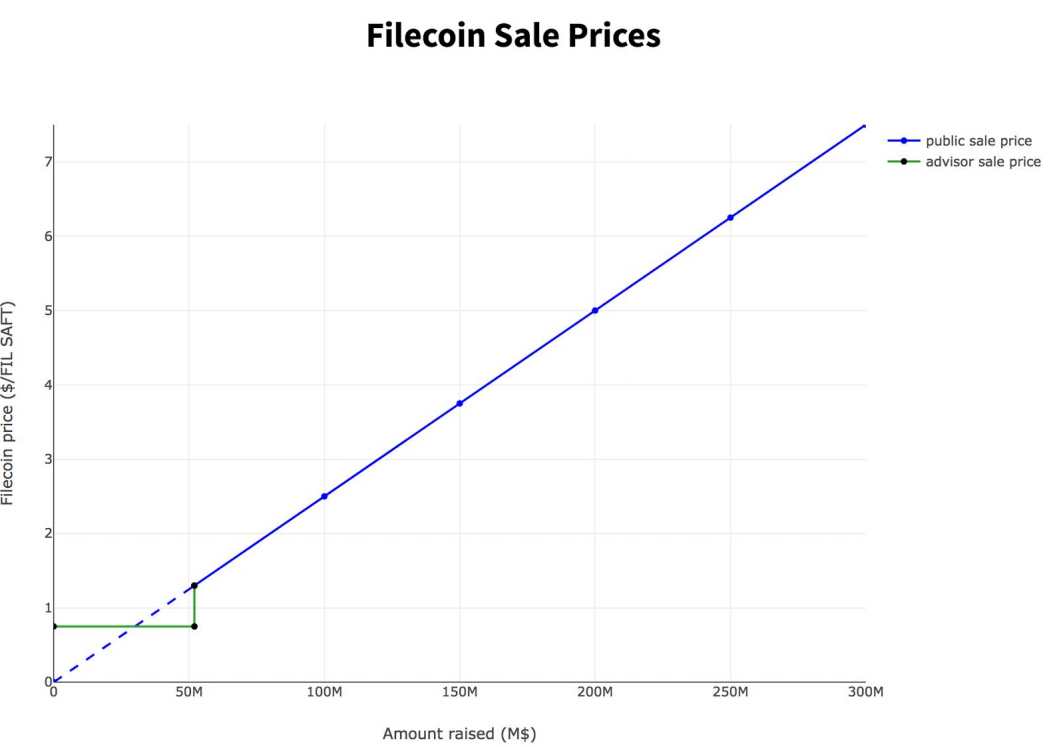
Despite this, these services have been raising extraordinary amounts of capital. For example, on September 7th last year Filecoin, one of the more credible efforts at a cryptocurrency-based storage service, closed a record-setting Initial Coin Offering:
Blockchain data storage network Filecoin has officially completed its initial coin offering (ICO), raising more than $257 million over a month of activity.
Filecoin's ICO, which began on August 10, quickly garnered millions in investment via CoinList, a joint project between Filecoin developer Protocol Labs and startup investment platform AngelList. That launch day was notable both for the large influx of purchases of Simple Agreements for Future Tokens, or SAFTs (effectively claims on tokens once the Filecoin network goes live), as well as the technology issues that quickly sprouted as accredited investors swamped the CoinList website.
Today, the ICO ended with approximately $205.8 million raised, a figure that adds to the $52 million collected in a presale that included Sequoia Capital, Andreessen Horowitz and Union Square Ventures, among others.
Lets believe for now these USD amounts (much of the ICO involved cryptocurrencies), and that the $257M is the capital for the business. Actually, only “a significant portion” is:
a significant portion of the amount raised under the SAFTs will be used to fund the Company’s development of a decentralized storage network that enables entities to earn Filecoin (the “Filecoin Network”).
Investors want a return on their investment, lets say 10%/yr. Ignoring the fact that:
The tokens being bought in this sale won’t be delivered until the Filecoin Network launches. Currently, there is no launch date set.
Filecoin needs to generate $25.7M/yr over and above what it pays the providers. But it can't charge the customers more than S3, or $0.276/GB/yr. If it didn't pay the providers anything it would need to be storing over 93PB right away to generate a 10% return. That's a lot of storage to expect providers to donate to the system.
Using 2016 data from Robert Fontana and Gary Decad of IBM, and ignoring the costs of space, power, bandwidth, servers, system administration, etc. the media alone represent $3.6M in capital. Lets assume a 5-year straight-line depreciation ($720K/yr) and a 10% return on capital ($360K/yr) that is $1.08M/yr to the providers just for the disks. If we assume the media are 1/3 of the total cost of storage provision, the system needs to be storing 107PB.
Another way of looking at these numbers is that Amazon's margins on S3 are awesome, something I first wrote about 5 years ago.
Running a P2 peer doesn't look like a good business, even ignoring the fact that only 70% of the Filecoin are available to be mined by storage suppliers. But wait! The cryptocurrency part adds the prospect of speculative gain! Oh no, it doesn't:
When Amazon launched S3 in March 2006 they charged $0.15 per GB per month.
Nearly 5 years later, S3 charges $0.14 per GB per month for the first TB.
As I write, their most expensive tier charges $0.023 per GB per month. In twelve years the price has declined by a factor of 6.5, or about 15%/yr. In the last seven years it has dropped about 23%/yr. Since its price is capped by S3's, one can expect that P2's cryptocurrency will decline by at least 15%/yr and probably 23%/yr. Not a great speculation once it gets up and running!
 |
| Source |
Like almost all cryptocurrencies, Filecoin is a way to transfer wealth from later to earlier participants. This was reflected in the pricing of the ICO; the price went up linearly with the total amount purchased, creating a frenzy that crashed the ICO website. The venture funds who put up the initial $50M, including Union Square Ventures, Andreessen Horowitz and Sequioa, paid less than even the early buyers in the ICO. The VCs paid about $0.80, the earliest buyer paid $1.30.
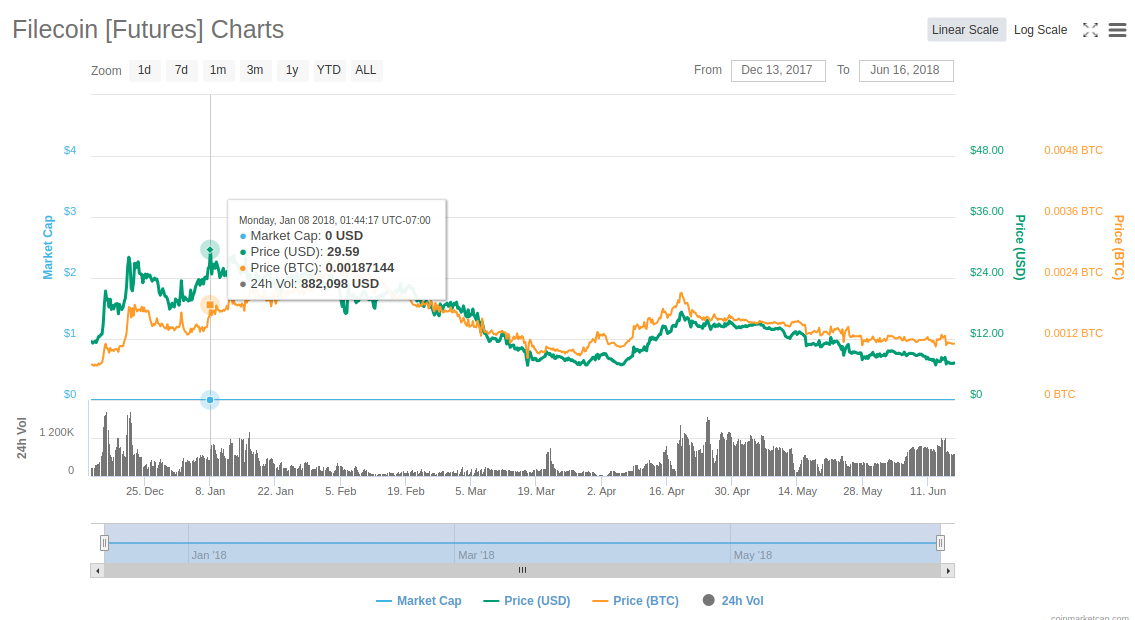
Filecoin is currently trading in the futures market at $7.26 , down from a peak at $29.59. The VCs are happy, having found many “greater fools” to whom their investment can, even now, be unloaded at nine times their cost. So are the early buyers in the ICO. The greater fools who bought at the peak have lost more than 70% of their money.
Ignoring for now the fact that running P2 peers won't be a profitable business in competition with S3, lets look at the effects of competition between P2 peers. As I wrote more than three years ago in Economies of Scale in Peer-to-Peer Networks:
The simplistic version of the problem is this:
- The income to a participant in a P2P network of this kind should be linear in their contribution of resources to the network.
- The costs a participant incurs by contributing resources to the network will be less than linear in their resource contribution, because of the economies of scale.
- Thus the proportional profit margin a participant obtains will increase with increasing resource contribution.
- Thus the effects described in Brian Arthur's Increasing Returns and Path Dependence in the Economy will apply, and the network will be dominated by a few, perhaps just one, large participant.
The advantages of P2P networks arise from a diverse network of small, roughly equal resource contributors. Thus it seems that P2P networks which have the characteristics needed to succeed (by being widely adopted) also inevitably carry the seeds of their own failure (by becoming effectively centralized).
Thus, as we see with Bitcoin, if the business of running P2 peers becomes profitable, the network will become centralized.
But that's not the worst of it. Suppose P2 storage became profitable and started to take business from S3. Amazon's slow AI has an obvious response, it can run P2 peers for itself on the same infrastructure as it runs S3. With its vast economies of scale and extremely low cost of capital, P2-on-S3 would easily capture the bulk of the P2 market. It isn't just that, if successful, the P2 network would become centralized, it is that it would become centralized at Amazon!
ROBERT STEELE: This is a sobering appreciation of the challenges to mesh networking from a person that is very very respected by my top crypto contacts. Below is what I said to them — the Amazon review of Clapper's book is an indirect indictment of the degree to which we all tolerate trillion dollar waste divorced from public need.
I am hoping you have a solution. The camera analogy comes to mind.
Throw-away cameras were anathema to the high end camera shops, but became a grocery store staple.
I just have a feeling there is a lego building block solution to all this but the idiot-proof plug and play architecture is not there yet
Imagine if Amazon were in charge of the human brain
I think they will implement predatory pricing on their competitors in next six to twelve months.
>Also Amazon is not in the business of selling storage space, it is in the business of attracting data from diverse clients that it can harvest in unique ways to create value for Amazon and Israel that cannot be created any other way — their returns are not financial, they are informational.
Below is my evisceration of Clapper's book — one trillion spent to no good end
Steele, Robert, “Grand Theft, Mass Murder and Legalized Lies – Book Review as Epitaph,” American Herald Tribune, 19 June 2018.
See Also:


