
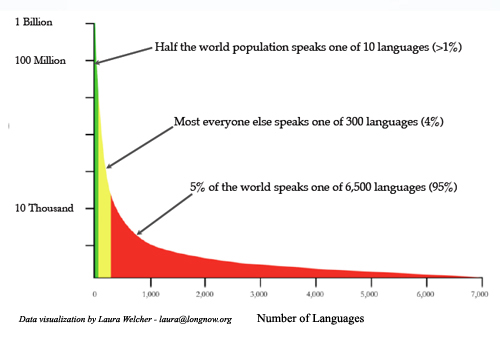
The Rosetta Project is pleased to announce the Parallel Speech Corpus Project, a year-long volunteer-based effort to collect parallel recordings in languages representing at least 95% of the world’s speakers. The resulting corpus will include audio recordings in hundreds of languages of the same set of texts, each accompanied by a transcription. This will provide a platform for creating new educational and preservation-oriented tools as well as technologies that may one day allow artificial systems to comprehend, translate, and generate them.
Continue reading “Building an Audio Collection for All the World’s Languages”






