The USB flash drive is one of the most simple, everyday pieces of technology that many people take for granted. Now it's being eyed as a possible solution to bridging the digital divide, by two colourful entrepreneurs behind the start-up Keepod. Nissan Bahar and Franky Imbesi aim to combat the lack of access to computers by providing what amounts to an operating-system-on-a-stick. In six weeks, their idea managed to raise more than $40,000 (£23,750) on fundraising site Indiegogo, providing the cash to begin a campaign to offer low-cost computing to the two-thirds of the globe's population that currently has little or no access. The test bed for the project is the slums of Nairobi in Kenya.
. . . . . . .
Very few people here use a computer or have access to the net. But Mr Bahar and Mr Imbesi want to change that with their Keepod USB stick. It will allow old, discarded and potentially non-functional PCs to be revived, while allowing each user to have ownership of their own “personal computer” experience – with their chosen desktop layout, programs and data – at a fraction of the cost of providing a unique laptop, tablet or other machine to each person. In addition, the project avoids a problem experienced by some other recycled PC schemes that resulted in machines becoming “clogged up” and running at a snail's pace after multiple users had saved different things to a single hard drive.
Preeminent scientists are warning about serious threats to human life in the not-distant future, including climate change and superintelligent computers. Most people don't care.
Sometimes Stephen Hawking writes an article that both mentions Johnny Depp and strongly warns that computers are an imminent threat to humanity, and not many people really care. That is the day there is too much on the Internet. (Did the computers not want us to see it?)
Hawking, along with MIT physics professorMax Tegmark, Nobel laureateFrank Wilczek, and Berkeley computer science professor Stuart Russell ran a terrifying op-ed a couple weeks ago in The Huffington Post under the staid headline “Transcending Complacency on Superintelligent Machines.” It was loosely tied to the Depp sci-fi thriller Transcendence, so that’s what’s happening there. “It's tempting to dismiss the notion of highly intelligent machines as mere science fiction,” they write. “But this would be a mistake, and potentially our worst mistake in history.”
And then, probably because it somehow didn’t get much attention, the exact piece ran again last week in The Independent, which went a little further with the headline: “Transcendence Looks at the Implications of Artificial Intelligence—but Are We Taking A.I. Seriously Enough?” Ah, splendid. Provocative, engaging, not sensational. But really what these preeminent scientists go on to say is not not sensational.
“An explosive transition is possible,” they continue, warning of a time when particles can be arranged in ways that perform more advanced computations than the human brain. “As Irving Good realized in 1965, machines with superhuman intelligence could repeatedly improve their design even further, triggering what Vernor Vinge called a ‘singularity.'”
Get out of here. I have a hundred thousand things I am concerned about at this exact moment. Do I seriously need to add to that a singularity?
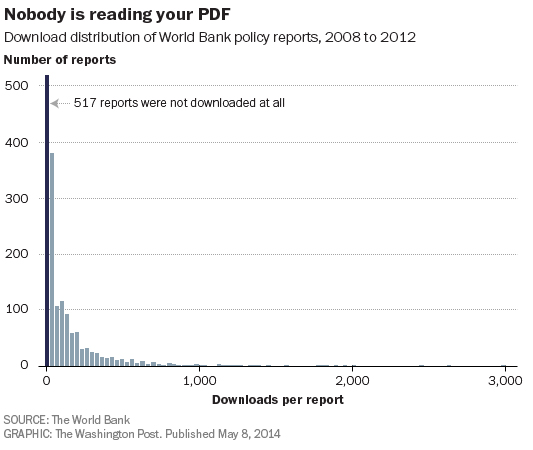
What if someone had already figured out the answers to the world's most pressing policy problems, but those solutions were buried deep in a PDF, somewhere nobody will ever read them?
Click on Image to Enlarge
According to a recent report by the World Bank, that scenario is not so far-fetched. The bank is one of those high-minded organizations — Washington is full of them — that release hundreds, maybe thousands, of reports a year on policy issues big and small. Many of these reports are long and highly technical, and just about all of them get released to the world as a PDF report posted to the organization's Web site.
The World Bank recently decided to ask an important question: Is anyone actually reading these things? They dug into their Web site traffic data and came to the following conclusions: Nearly one-third of their PDF reports had never been downloaded, not even once. Another 40 percent of their reports had been downloaded fewer than 100 times. Only 13 percent had seen more than 250 downloads in their lifetimes. Since most World Bank reports have a stated objective of informing public debate or government policy, this seems like a pretty lousy track record.
I think the evidence is now in, and it seems quite clear, as this story describes. The toxins produced by companies like Monsanto and Dow are literally putting the world's food supply at risk. It is going to be very interesting to watch how the Obama Administration reacts. He has proven to be so disappointing in so many ways, but this is a clear and urgent da! nger. We are about to see whether Obama thinks profit for a few corporations is more important than the wellbeing of all humanity.
Honeybees exposed to a certain class of insecticide are more likely to die from Colony Collapse Disorder (CCD), the name given to whatever is causing a mass decline in the bee population over the past six years, according to a new study.
The sobering story of Janet Vertesi's attempts to conceal her pregnancy from the forces of online marketers shows just how Kafkaesque the internet has become
John Naughton
The Observer, 10 May 2014
When searching for an adjective to describe our comprehensively surveilled networked world – the one bookmarked by the NSA at one end and by Google, Facebook, Yahoo and co at the other – “Orwellian” is the word that people generally reach for.
But “Kafkaesque” seems more appropriate. The term is conventionally defined as “having a nightmarishly complex, bizarre, or illogical quality”, but Frederick Karl, Franz Kafka's most assiduous biographer, regarded that as missing the point. “What's Kafkaesque,” he once told the New York Times, “is when you enter a surreal world in which all your control patterns, all your plans, the whole way in which you have configured your own behaviour, begins to fall to pieces, when you find yourself against a force that does not lend itself to the way you perceive the world.”
A vivid description of this was provided recently by Janet Vertesi, a sociologist at Princeton University. She gave a talk at a conference describing her experience of trying to keep her pregnancy secret from marketers. Her report is particularly pertinent because pregnant women are regarded by online advertisers as one of the most valuable entities on the net. You and I are worth, on average, only 10 cents each. But a pregnant woman is valued at $1.50 because she is about to embark on a series of purchasing decisions stretching well into her child's lifetime.
Professor Vertesi's story is about big data, but from the bottom up. It's a gripping personal account of what it takes to avoid being collected, tracked and entered into databases.
. . . . . . . .
In preparing for the birth of her child, Vertesi was nothing if not thorough. Instead of using a web-browser in the normal way – ie leaving a trail of cookies and other digital tracks, she used the online service Tor to visit babycenter.com anonymously. She shopped offline whenever she could and paid in cash. On the occasions when she had to use Amazon, she set up a new Amazon account linked to an email address on a personal server, had all packages delivered to a local locker and made sure only to pay with Amazon gift cards that had been purchased with cash.
The really significant moment came when she came to buy a big-ticket item – an expensive stroller (aka pushchair) that was the urbanite's equivalent of an SUV. Her husband tried to buy $500 of Amazon gift vouchers with cash, only to discover that this triggered a warning: retailers have to report people buying large numbers of gift vouchers with cash because, well, you know, they're obviously money launderers.
. . . . . . . .
Even more sobering, though, are the implications of Professor Vertesi's decision to use Tor as a way of ensuring the anonymity of her web-browsing activities. She had a perfectly reasonable reason for doing this – to ensure that, as a mother-to-be, she was not tracked and targeted by online marketers.
But we know from the Snowden disclosures and other sources that Tor users are automatically regarded with suspicion by the NSA et al on the grounds that people who do not wish to leave a digital trail are obviously up to no good. The same goes for people who encrypt their emails.
Supporters of the National Security Agency inevitably defend its sweeping collection of phone and Internet records on the ground that it is only collecting so-called “metadata”—who you call, when you call, how long you talk. Since this does not include the actual content of the communications, the threat to privacy is said to be negligible. That argument is profoundly misleading. Of course knowing the content of a call can be crucial to establishing a particular threat. But metadata alone can provide an extremely detailed picture of a person’s most intimate associations and interests, and it’s actually much easier as a technological matter to search huge amounts of metadata than to listen to millions of phone calls. As NSA General Counsel Stewart Baker has said, “metadata absolutely tells you everything about somebody’s life. If you have enough metadata, you don’t really need content.” When I quoted Baker at a recent debate at Johns Hopkins University, my opponent, General Michael Hayden, former director of the NSA and the CIA, called Baker’s comment “absolutely correct,” and raised him one, asserting, “We kill people based on metadata.”
After reading an article called “How Google Earth Works” on the great site HowStuffWorks.com, it became apparent that the article was more of a “how cool it is” and “here’s how to use it” than a “how Google Earth [really] works.”
So I thought there might be some interest, and despite some valid intellectual property concerns, here we are, explaining how at least part of Google Earth works.
Keep in mind, those IP issues are real. Keyhole (now known as Google Earth) was attacked once already with claims that they copied someone else’s inferior (IMO) technology. The suit was completely dismissed by a judge, but only after many years of pain. Still, it highlights one problem of even talking about this stuff. Anything one says could be fodder for some troll to claim heinvented what you did because it “sounds similar.” The judge in the Skyline v. Google case understood that “sounding similar” is not enough to prove infringement. Not all judges do.
Anyway, the solution to discussing “How Google Earth [Really] Works” is to stick to information that has already been disclosed in various forms, especially in Google’s own patents, of which there are relatively few. Fewer software patents is better for the world. But in this case, more patents would mean we could talk more openly about the technology, which, btw, was one of the original goals of patents — a trade of limited monopoly rights in exchange for a real public benefit: disclosure. But I digress…
For the more technically inclined, you may want to read these patents directly. Be warned: lawyers and technologists sometimes emulsify to form a sort of linguistic mayonnaise, a soul-deadening substance known as Patent English, or Painglish for short . If you’re brave, or masochistic, here you go:
There are also a few more loosely related Google patents. I don’t know why these are shouting, but perhaps because they’re very important to the field. I’ll hopefully get to these in more detail in future articles:
And there is this more informative technical paper from SGI (PDF) on hardware “clipmapping,” which we’ll refer to later on. Michael Jones, btw, is one of the driving forces behind Google Earth, and as CTO, is still advancing the technology.
I’m going to stick closely to what’s been disclosed or is otherwise common technical knowledge. But I will hopefully explain it in a way that most humans can understand and maybe even appreciate. At least that’s my goal. You can let me know.
Big Caveat: the Google Earth code base has probably been rewritten several times since I was involved with Keyhole and perhaps even after these patents were submitted. Suffice it to say, the latest implementations may have changed significantly. And even my explanations are going to be so broad (and potentially out-dated) that no one should use this article as the basis for anything except intellectual curiosity and understanding.
Also note: we’re going to proceed in reverse, strange as it may seem, from the instant the 3D Earth is drawn on your screen, and later trace back to the time the data is served. I believe this will help explain why things are done as they are and why some other approaches don’t work nearly as well.
Late last week ESRI announced that its ArcGIS Online services will be migrating to the Mercator-based tiling scheme used by Google Maps and Bing Maps by the end of the year. Previously these services have used the WGS 1984 geographic coordinate system with a 512 x 512 pixel size. Google Maps and Bing use a modified Mercator projection with a 256 x 256 tiles size. The differences between ArcGIS Online and the popular Google Maps and Bing tiling schemes caused problems for many organizations. According to ESRI,
Some organizations struggle with choosing either the ArcGIS Online tiling scheme to match their ESRI software stack, or the Google / Bing tiling scheme to match a better-known standard. With a unified tiling scheme for the three services, the decision gets a lot easier.
The post goes on to discuss the advantages and challenges of switching to the new tiling scheme and also discusses a workflow for caching your maps in the new scheme.